
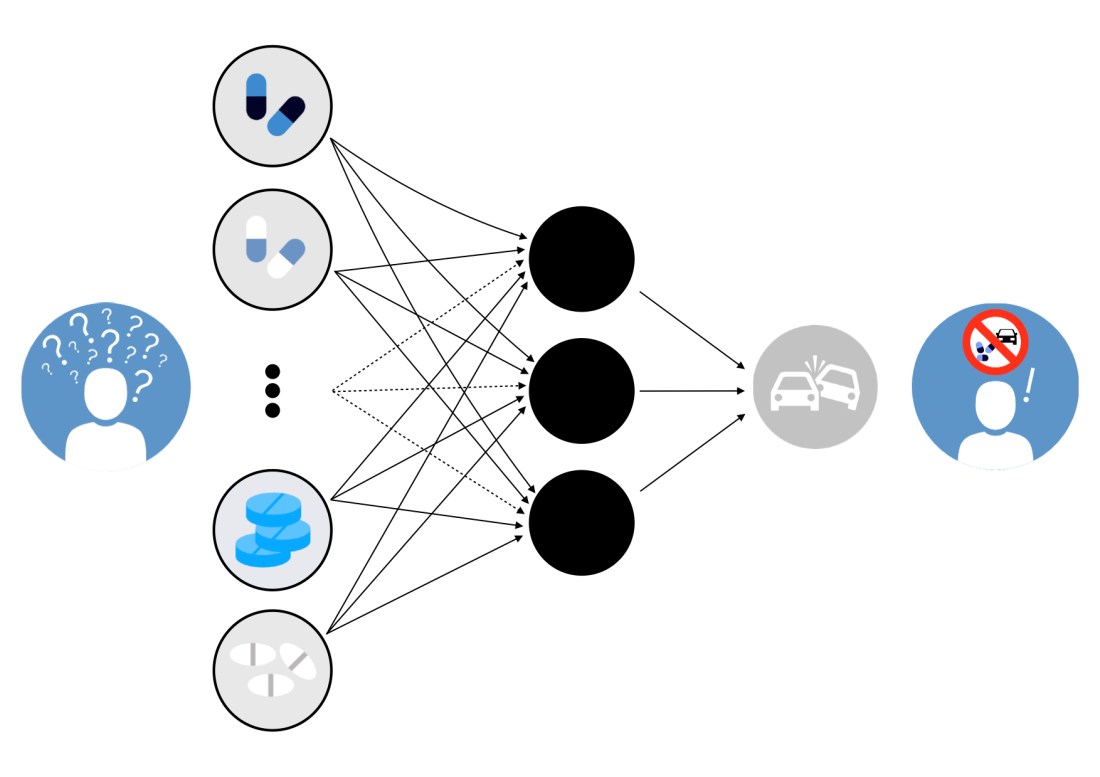
Lorsqu’on s’intéresse à des questions telles que « quels médicaments, parmi ce grand nombre, sont associés à cet évènement de santé d’intérêt ? », des problèmes statistiques de multiplicité de test peuvent se produire. Des méthodes qui visent à réduire la dimension, telles que la régression Lasso ou les forêts aléatoires, issues de l’apprentissage statistique (Statistical Machine Learning) ont connu depuis quelques années des développements théoriques, méthodologiques et algorithmiques très importants, lorsque les observations sont indépendantes. Par exemple, la méthode Lasso a été préalablement appliquée avec succès à l’étude CESIR (Combinaison d’Etudes sur la Santé et l’Insécurité Routière), dont les données concernant l’exposition aux médicaments sont issues du SNIIRAM et les événements d’intérêt sont l’implication/responsabilité dans un accident de la route.
L’utilisation des bases de données médico-administratives permet d’envisager la prise en compte, d’une part, de l’exposition à plusieurs médicaments (données de grande dimension) et, d’autre part, de la nature longitudinale de l’exposition médicamenteuse, et cela pour un grand nombre de sujets (données à large échelle). Dans le cas de CESIR, peut-on encore améliorer la précision en prédiction d’accident de la route en tirant profit de toute l’information disponible sur les 6 mois qui ont précédé l’accident par l’utilisation des méthodes statistiques d’apprentissage automatique ? Si cette amélioration s’avère importante, certes nous ne pourrons pas dégager directement des liens de causalité, mais cela nous permettra d’ouvrir de nouvelles pistes de recherche sur la caractérisation des profils de consommation de médicaments liés à un sur-risque d’accident de la route.
L’objectif est d’appliquer à l’étude CESIR les méthodes statistiques d’apprentissage automatique classiques pour l’analyse de données de grande dimension (Lasso, forêts aléatoires, réseaux de neurones).
Valorisation de la recherche


Communications en congrès

Avertissement : Le contenu de la publication n’engage que ses auteurs et ne reflète pas nécessairement la position de l’ANSM
